Alexaで日本語で開発できるようになったから、サクット作る流れをメモで残しておく。詳細はAmazonの資料だけど、見てもなかなか分からなかったり、謎な部分のお助けになれば。
■ 利用するもの
登録はやっておきましょう。
– Alexaの管理画面(日本版) : https://alexa.amazon.co.jp
– Alexaの管理画面(こっちは米国版) : https://alexa.amazon.com
– Amazonの開発者ポータル : https://developer.amazon.com/edw/home.html#/
– AWS Lambda : https://console.aws.amazon.com/lambda/
ここではサンプルで使われるLambdaのサンプルにもある「色をAlexaに言わせるスキル」の簡易版を作る。どういったものか?と言うと、Alexaに向かって、
自分:「好きな色は赤です。」
Alexa:「あなたの好きな色は赤ですね。」
と色を反芻して言ってくれるもので、基礎的だけど初歩としては簡単な1歩になると思われ。ということで進めていく。
■ Amazonの開発者ポータルで情報を入力する
1. Alexaの開発者ポータルにログイン
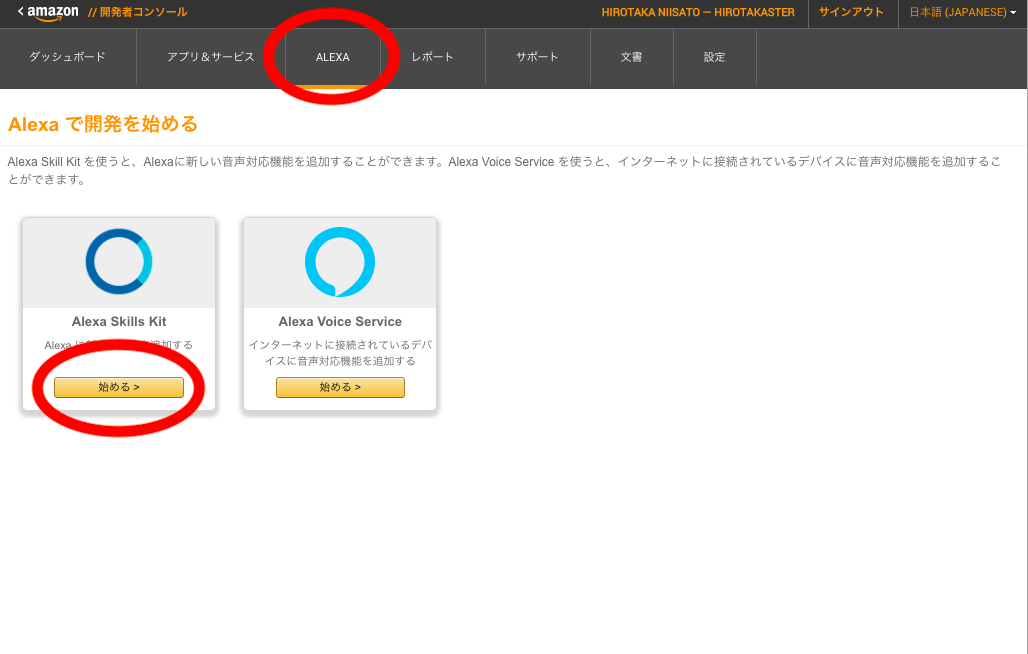
2. 新しいスキルを作っていくボタンをぽちる
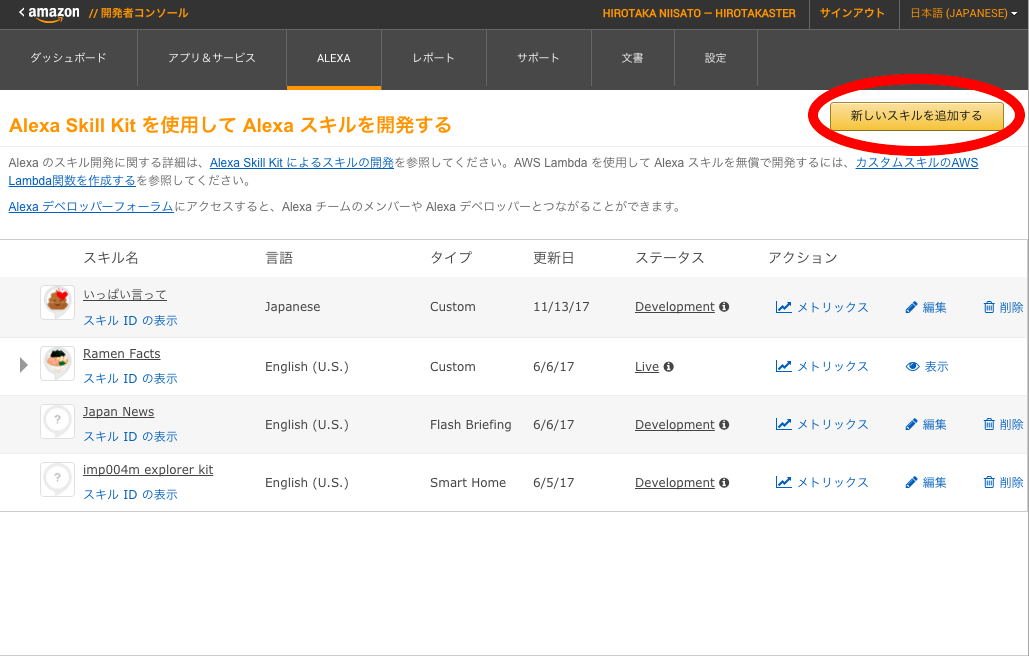
3.1. スキルの情報を入れていく
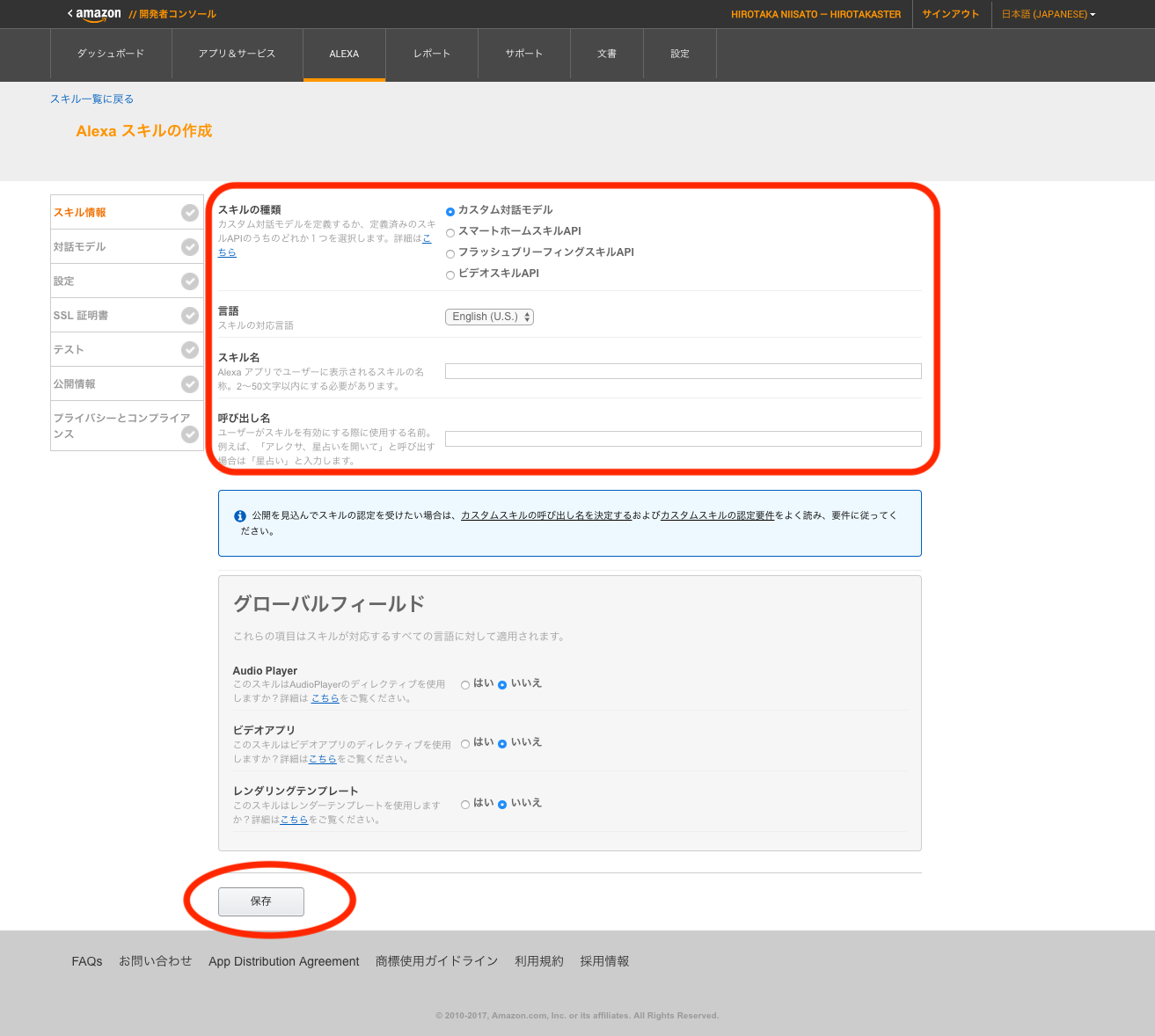
言語で日本語を選択できる。スキルの種類については、こちらを参照。自分が使いやすくて感動したのはスマートホームスキル。
3.2. スキルの情報をいれた結果
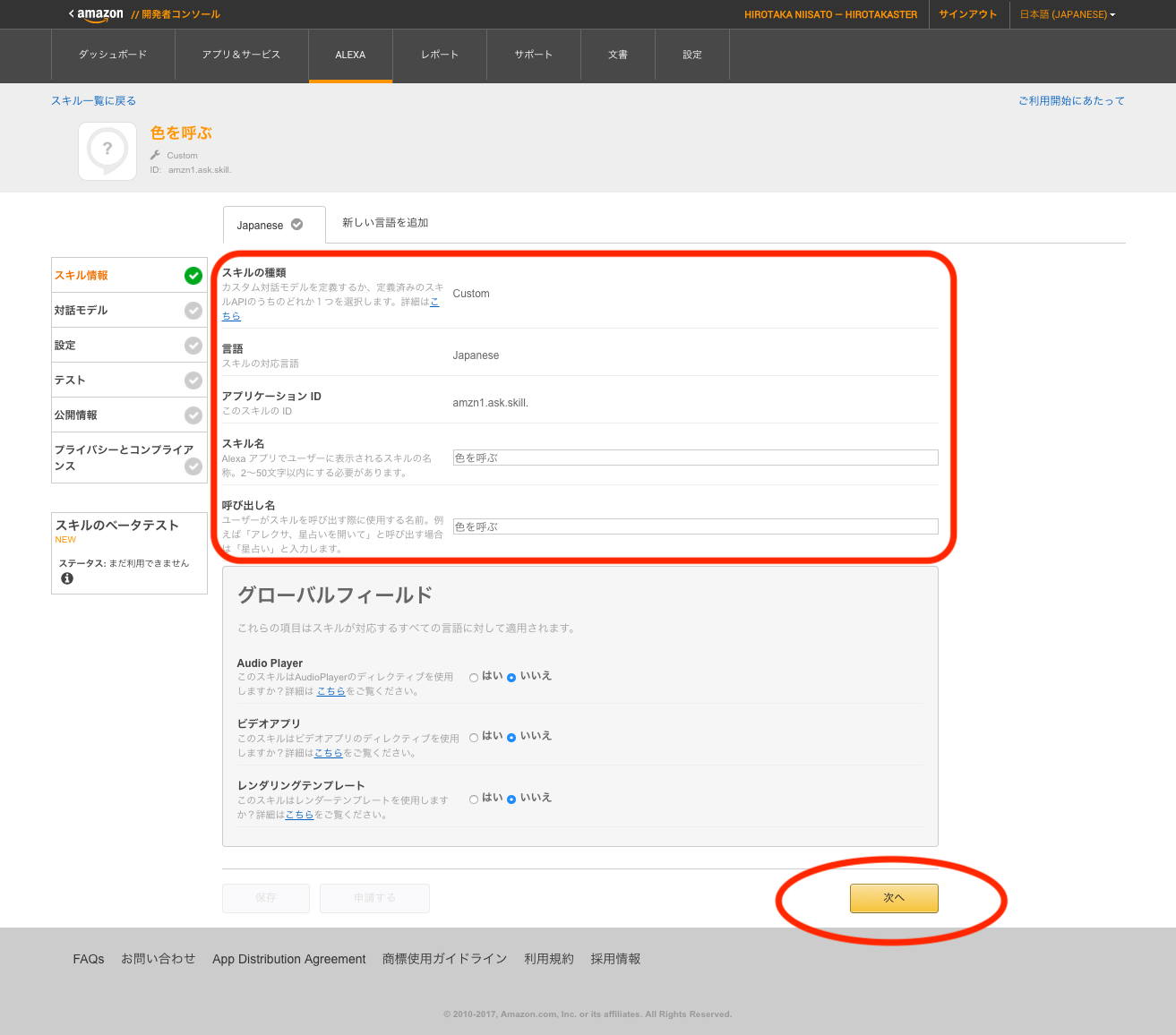
適当に名前を入れる。呼び出し名は「Alexa、なんちゃらかんちゃら」とスキルを起動するときの”なんちゃらかんちゃら”の部分。名前と呼び出し名を一緒にしておくと、分かりやすくて良いと思われ。もちろん、日本語名が使える。
そして、アプリケーションIDが発行される。この”アプリケーションID“のIDはあとでLambdaで利用する。
4.1.対話モデルを作っていく
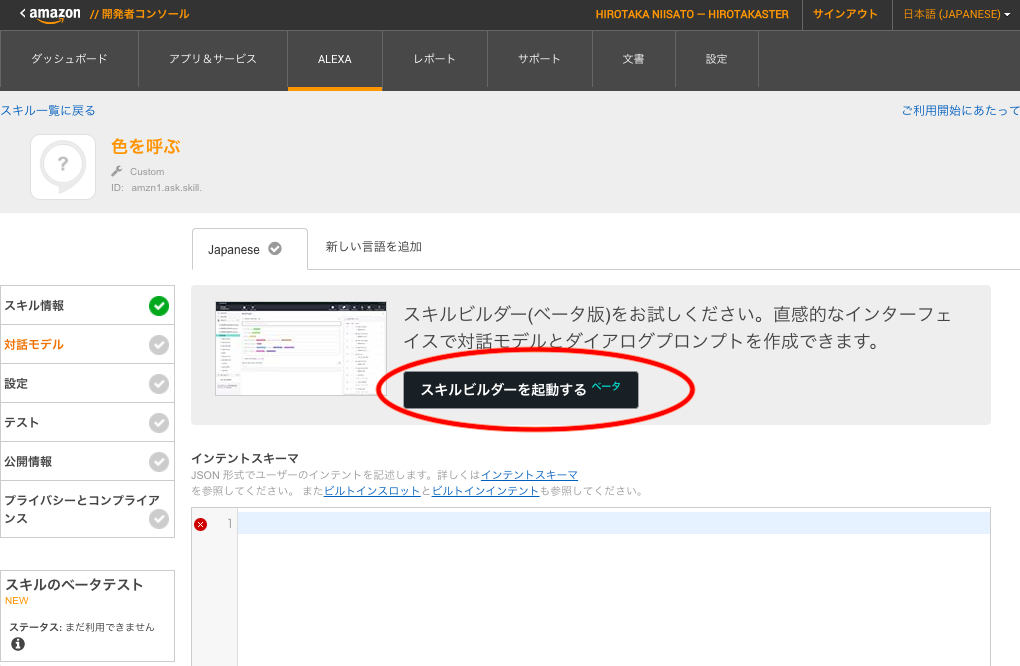
スキルビルダーをポチって画面遷移
4.2.スキルビルダー画面
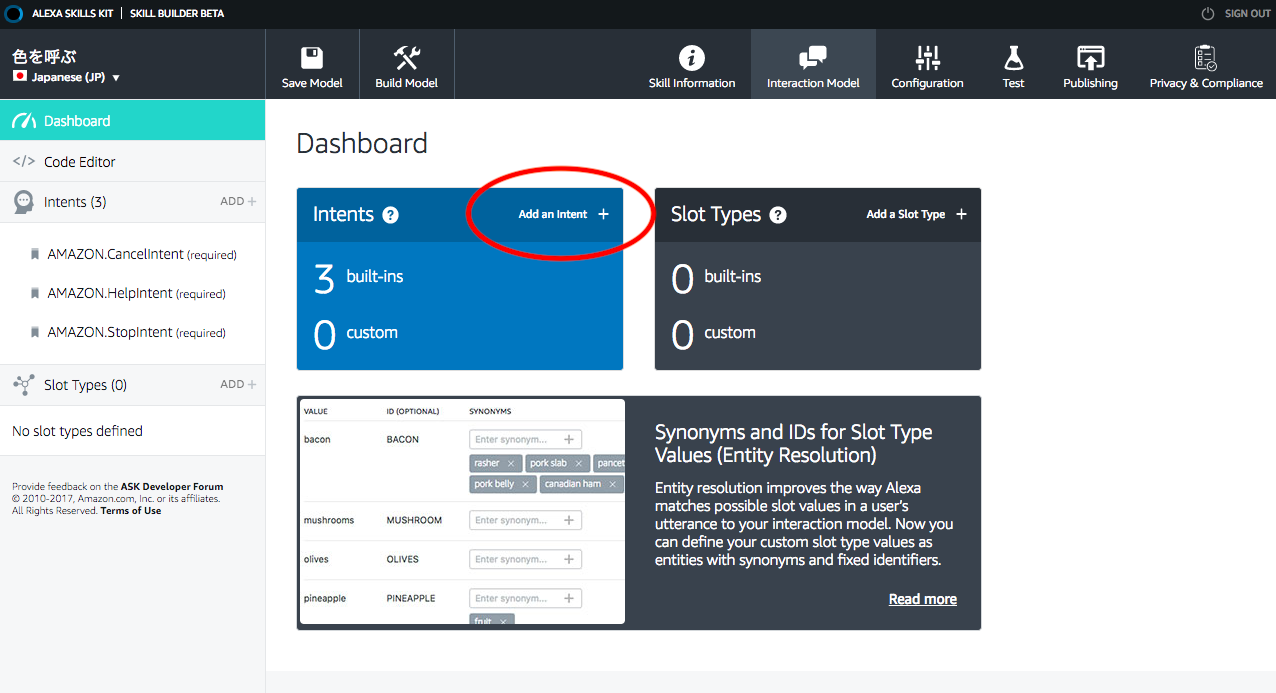
ここで対話モデルを作っていく。ザックリだと、
1. Alexaに話しかける話の構造(Intent)
2. 話しかけた結果から取得できる変数の設定(Slot)
3. 変数に割り当てることができる値の定義(SlotTypeに値を割り当て)
といった感じ。ここで設定した名前が後でAWS Lambdaのプログラム側で利用できるようになる。例えば、次から設定する流れだと、
1.1. Intentの名前を決める(MyColorsIntent)
1.2. 話しかける内容をつくる(“好きな色は {Color} です”と話かけられるようにする。ここで {Color} は可変の値。)
2.1. 変数(Slot)の設定を行う。
2.1. Slotのタイプを作る(Color_ITEM_LIST)
3.1. 変数に割当られる値の定義(緑、赤、青…etc)を入れていく
つまり、Alexaに話かける内容はここで決める。「怪しい {Color} は何ですか?」「{Color}をもう一度言ってくれますか」といった話を入れていったりする。
なにはともあれ、”Intentの+”ボタンをクリック。
4.3.Intentの名前を決める
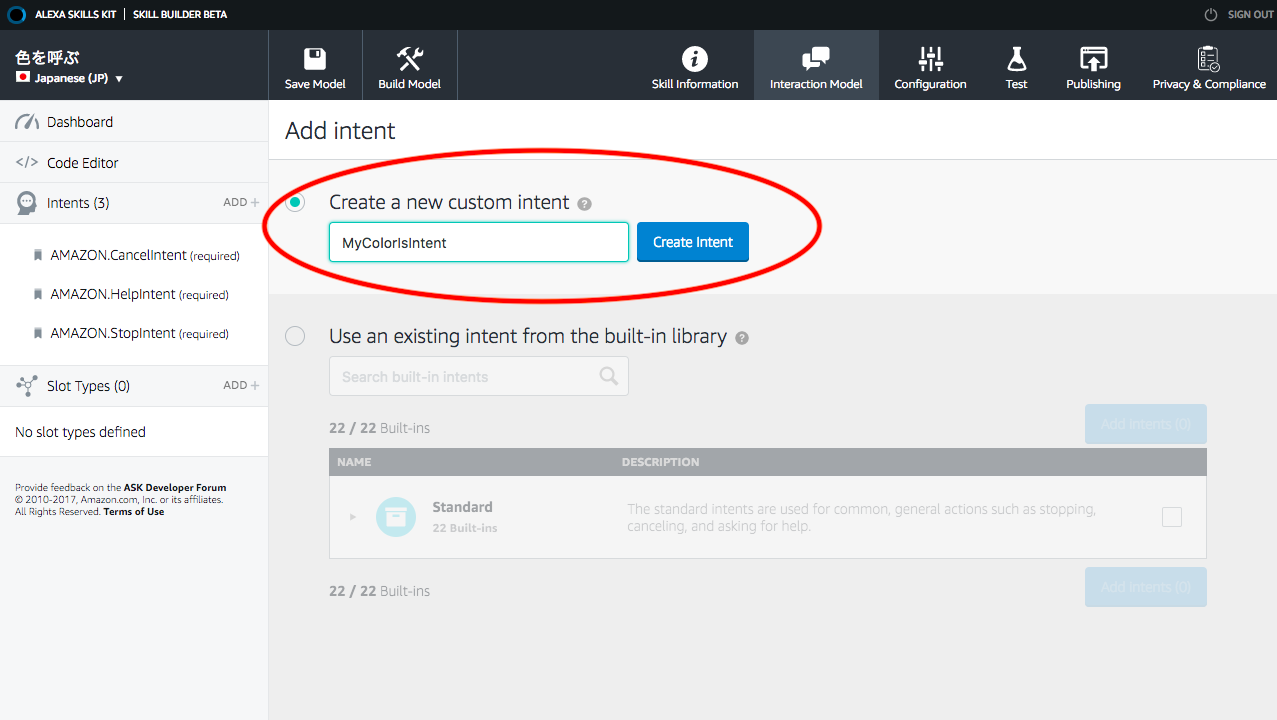
ここでは”MyColorsIntent”という名前にする。この名前はあとでLambdaで利用する。この名称に日本語は利用できない。
4.4.話しかける内容をつくる
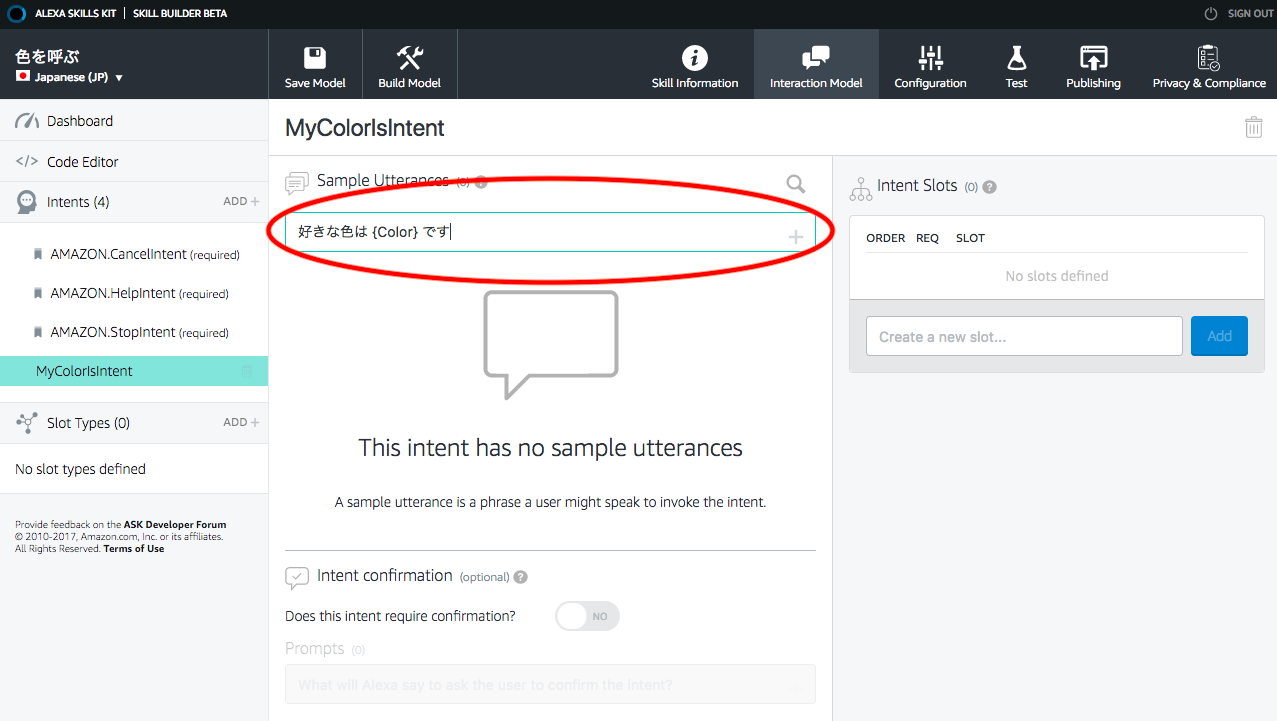
「好きな色は {Color} です。」と入れて”+”をクリック。この時、{}の前後に半角スペースを1個いれる。これを入れないとモデルを作る時にエラーになる。
4.5.Slotの設定を行う
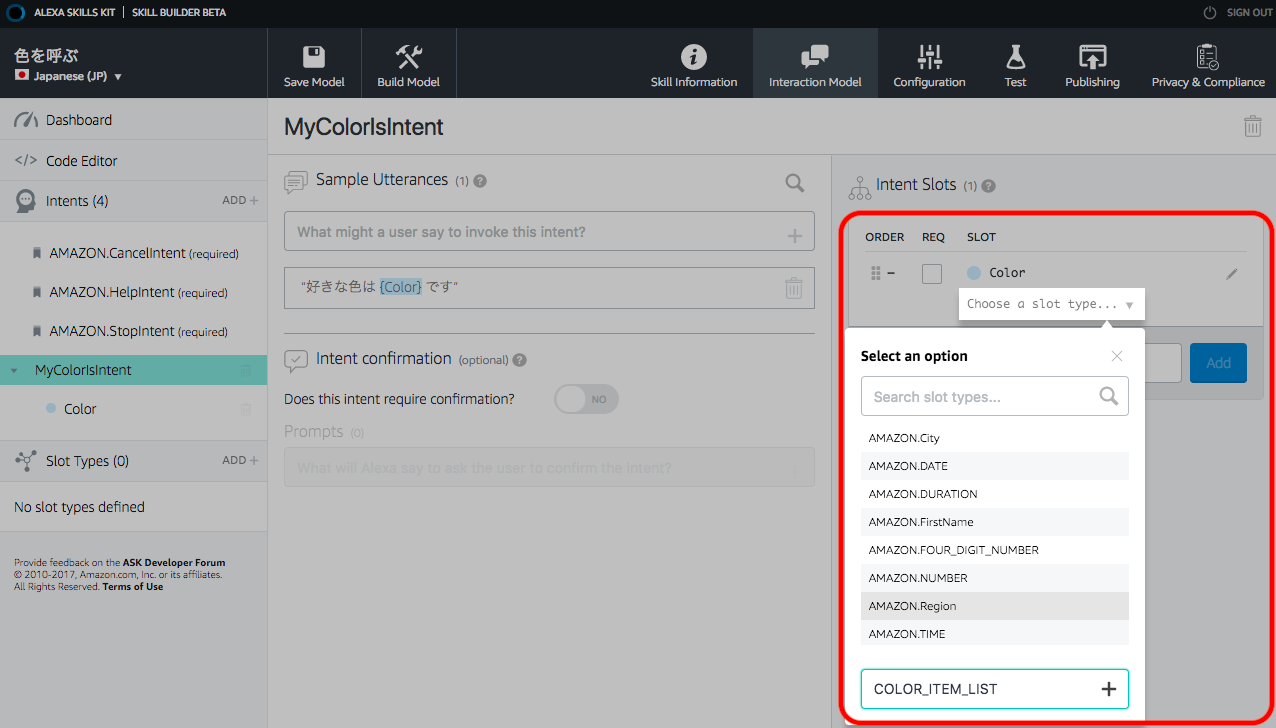
右側のタブに”Color”という項目が追加されるので、その下にある”Choose a slot type…”をクリックするとリストが出てくる。ここで、新規に”COLOR_ITEM_LIST”を追記&作成して”+”をクリック。
割り当てたSlot(変数)には型が必要で、デフォルトで利用できるもので、AMAZON.City, AMAZON.DATE…etcが並んでいる。TEXTやStringといった文字列が無いのが辛い(少し昔はあったけど、無くなってしまった)。自作スキルでデフォルトで利用できる型があればそれを使った方がOK。大抵の場合は使いたい型が無いと思うので、自分で型を作ることになると思われ。
4.6.Slotに割当られる値の定義
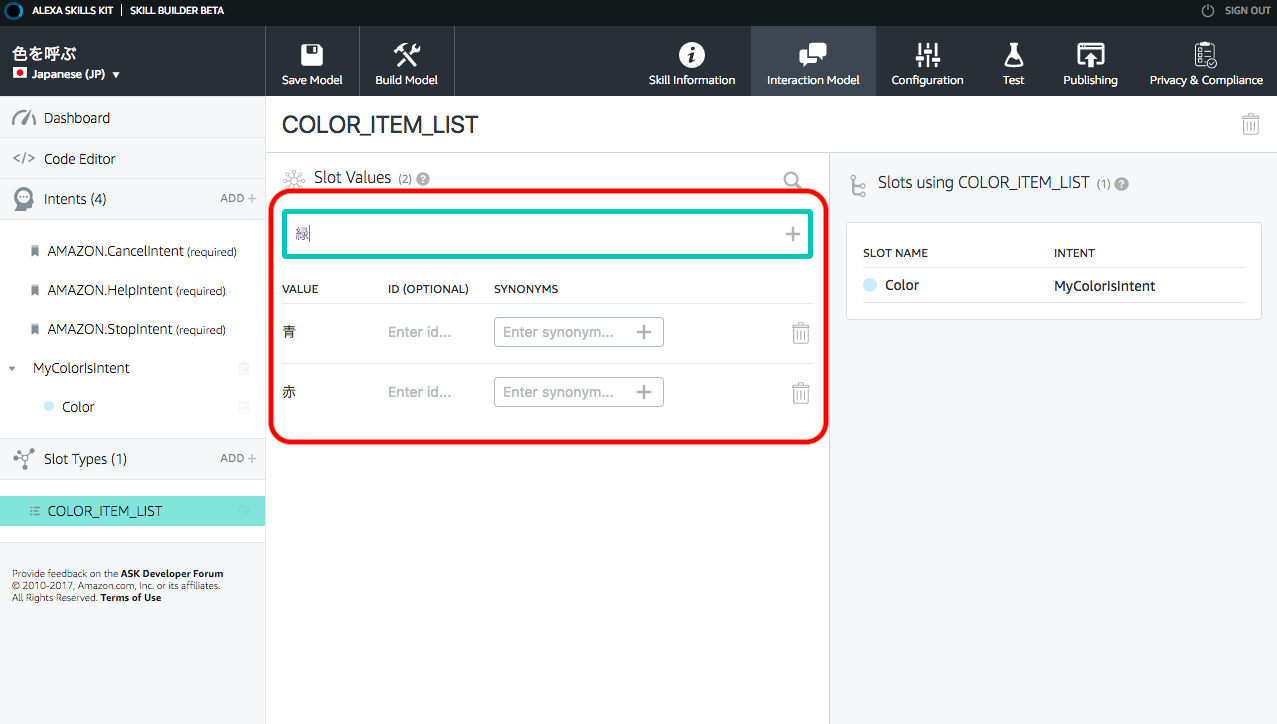
「赤、緑、青…etc」を入れて”+”を押して、Slotに割当られる値を定義していく。ここで割り当てた値が、あとで作るLambdaで利用することが出来る。
設定関係はここまで。
5.作ったモデルを見てみる
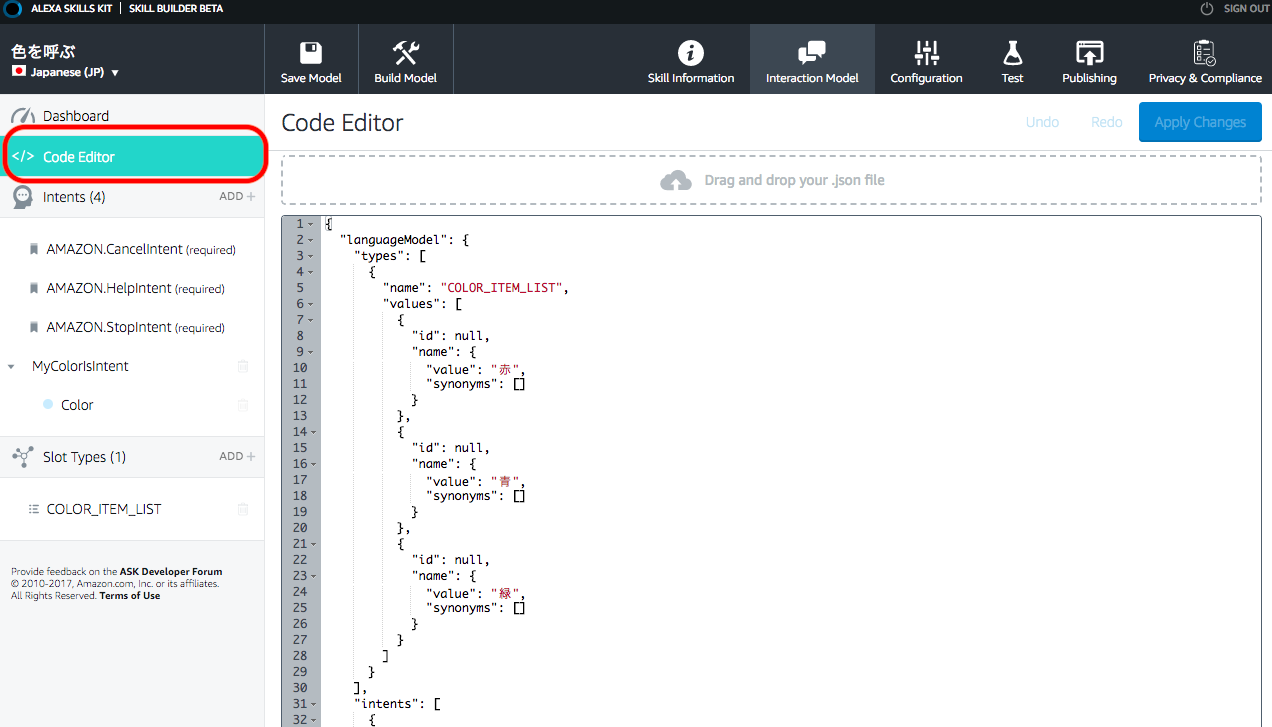
“Code Editor”をクリックすると、作ったモデルのJSONの表現が見れる。ここで直接、モデルを記載していってもOK。
6.モデルの保存とビルド
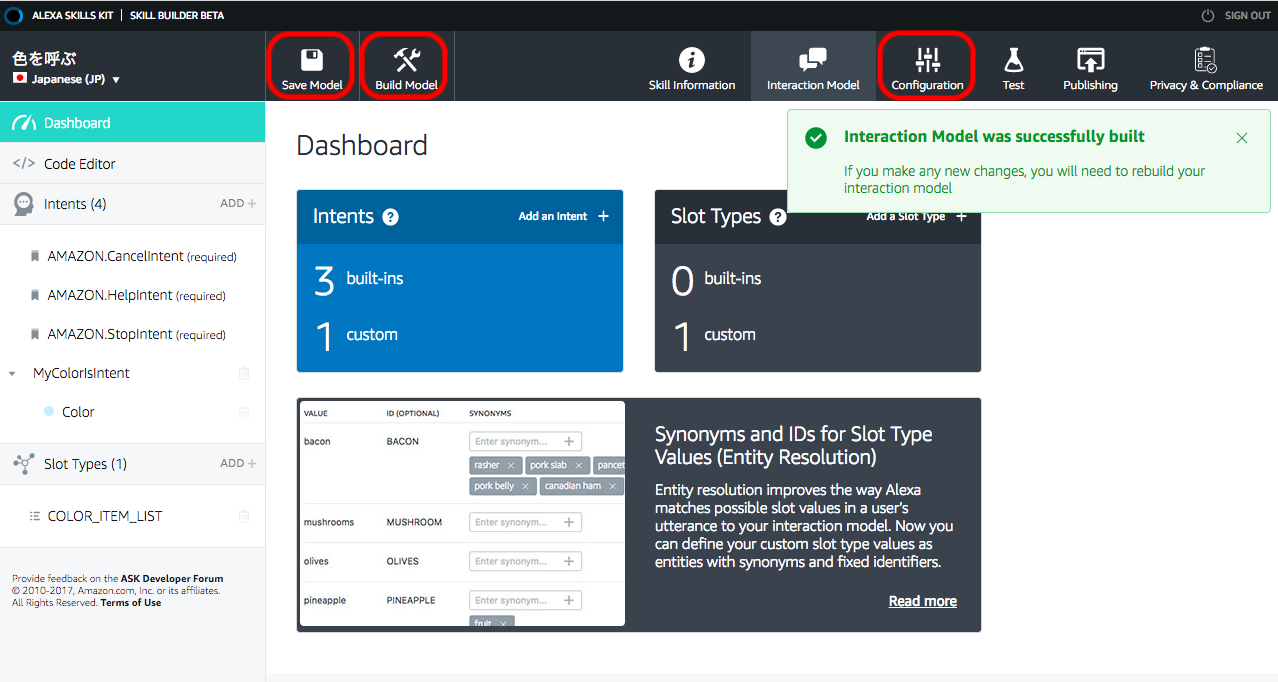
“Save Model” -> “Build Model”で作ったモデルをビルドしておく。終わったら”Configuration”ボタンをクリックして、作ったスキルの設定をしていく。
7.Alexaの設定画面
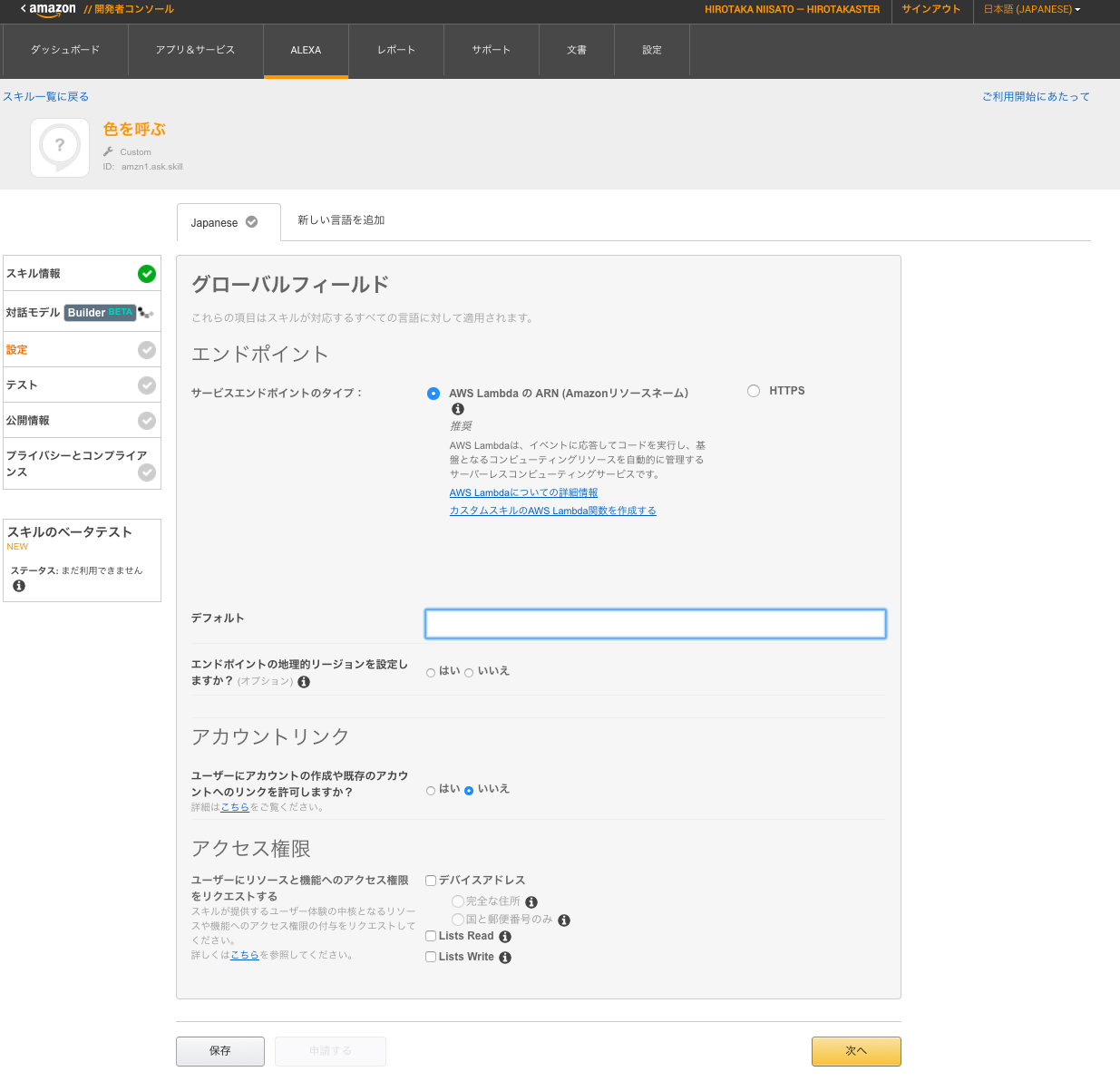
ここでAWS Lambda(プログラム側)との連携の設定をする。サービスエンドポイントはAWS Lambda(HTTPS側で自前サーバも可)で、デフォルトのテキストボックスの所にLambda側のARNエンドポイントを入れる。まだLambad側は作っていないので、とりあえずAlexa側の設定はここまで。次にLambdaでプログラム側の設定をしていく。
■ LambdaでAlexaスキルを作っていく
1. Lambdaの関数を作る。
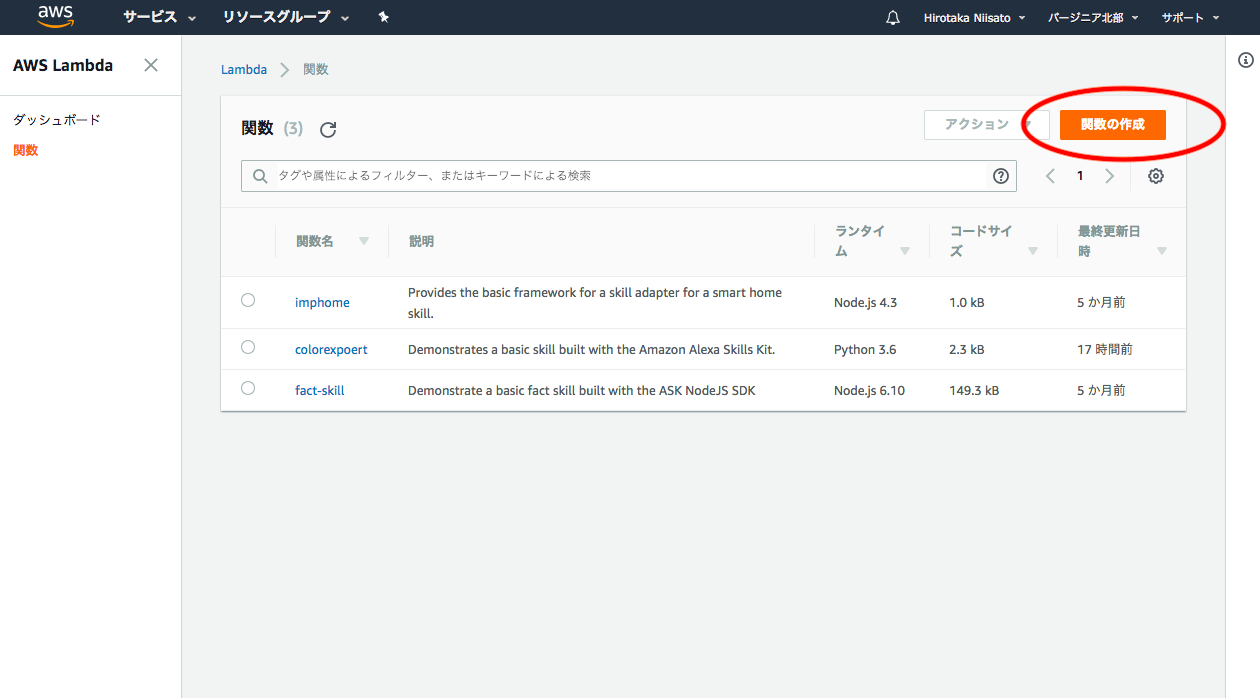
AWS Lambdaの詳しい説明はググればOK。ザックリだと、サーバを作らなくてもアプリでスケールしてくれるPaaSといった感じ。何はともあれ「関数の作成」をクリック。
2. 関数の作成
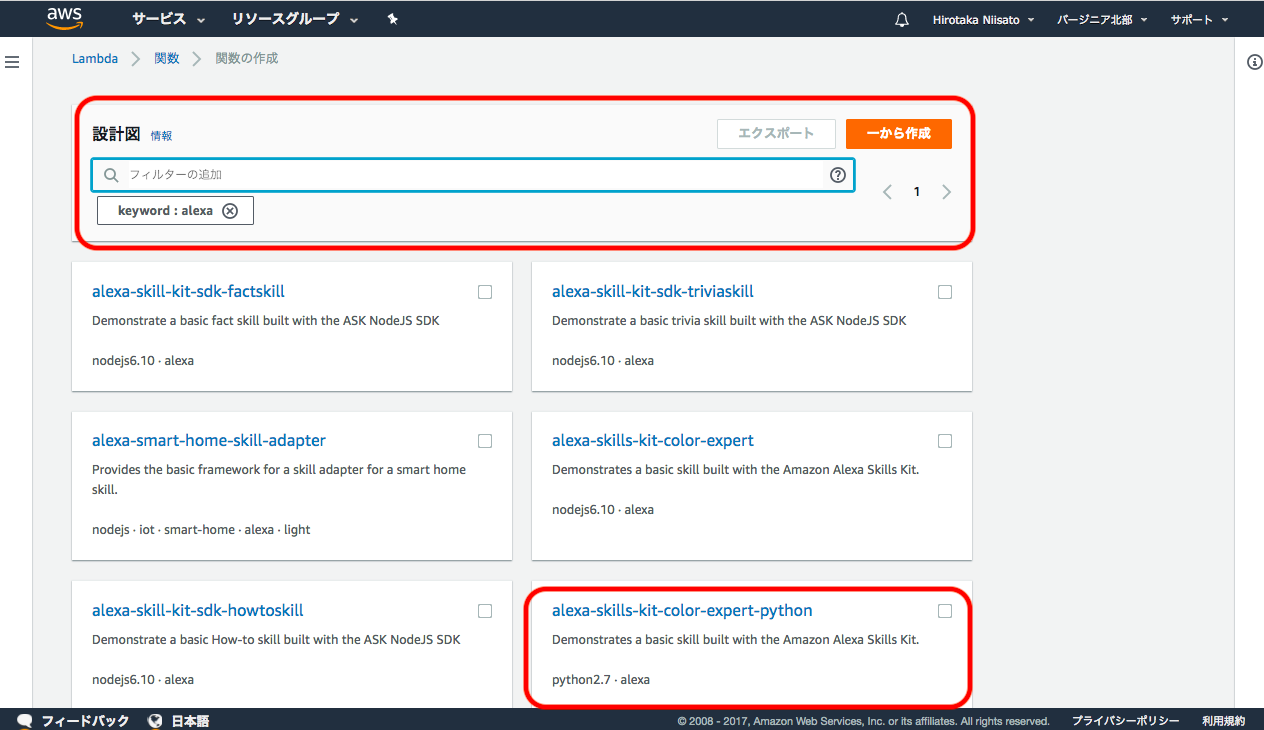
テキストボックスの所に”Alexa”と入れると、Alexaで利用できる関数一覧が出てくるので、”Alexa-skills-kit-color-expert-python”をクリック。
3. 関数の設定
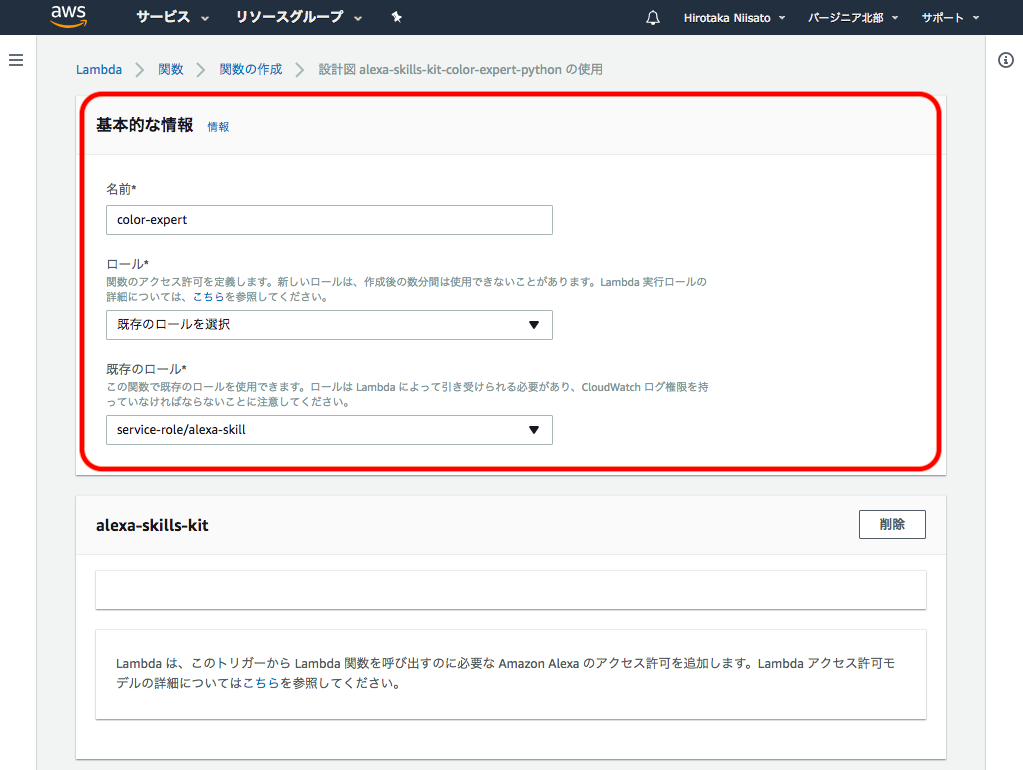
作成する関数の”名前”、ロールは既存のロールで、”service-role/alexa-skill”を選択。
ページの一番下にある”関数の作成”ボタンをクリック。
4. 関数の作成完了
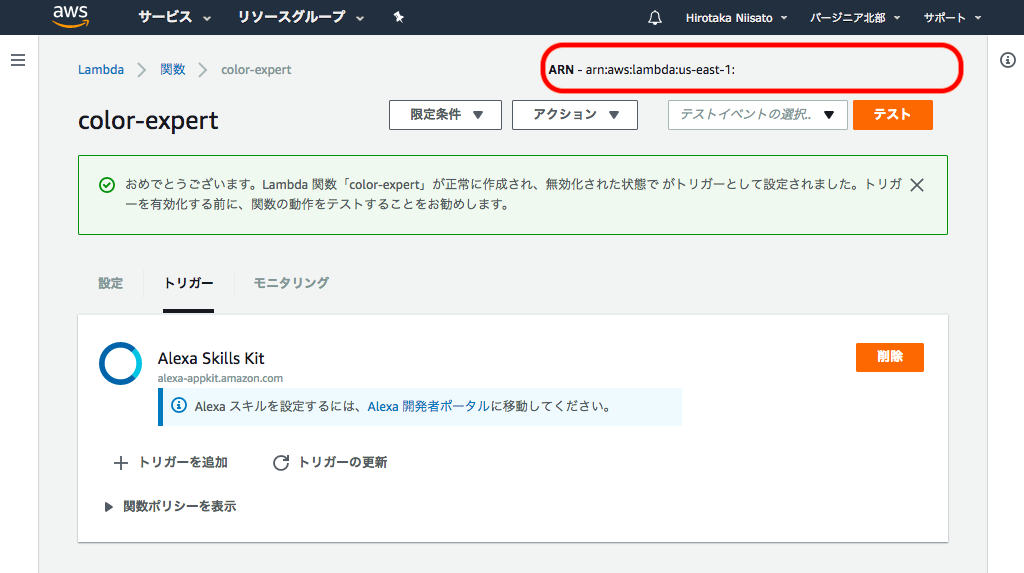
これでLambda側の関数が作成できた。サンプル通りで非常に簡単。次に赤枠にある部分のARNという部分をコピーしておいて、実際にAlexa側と連携させてテストをする。
■ Amazonの開発者ポータルでスキルのテスト
1. AlexaとLambdaの連携
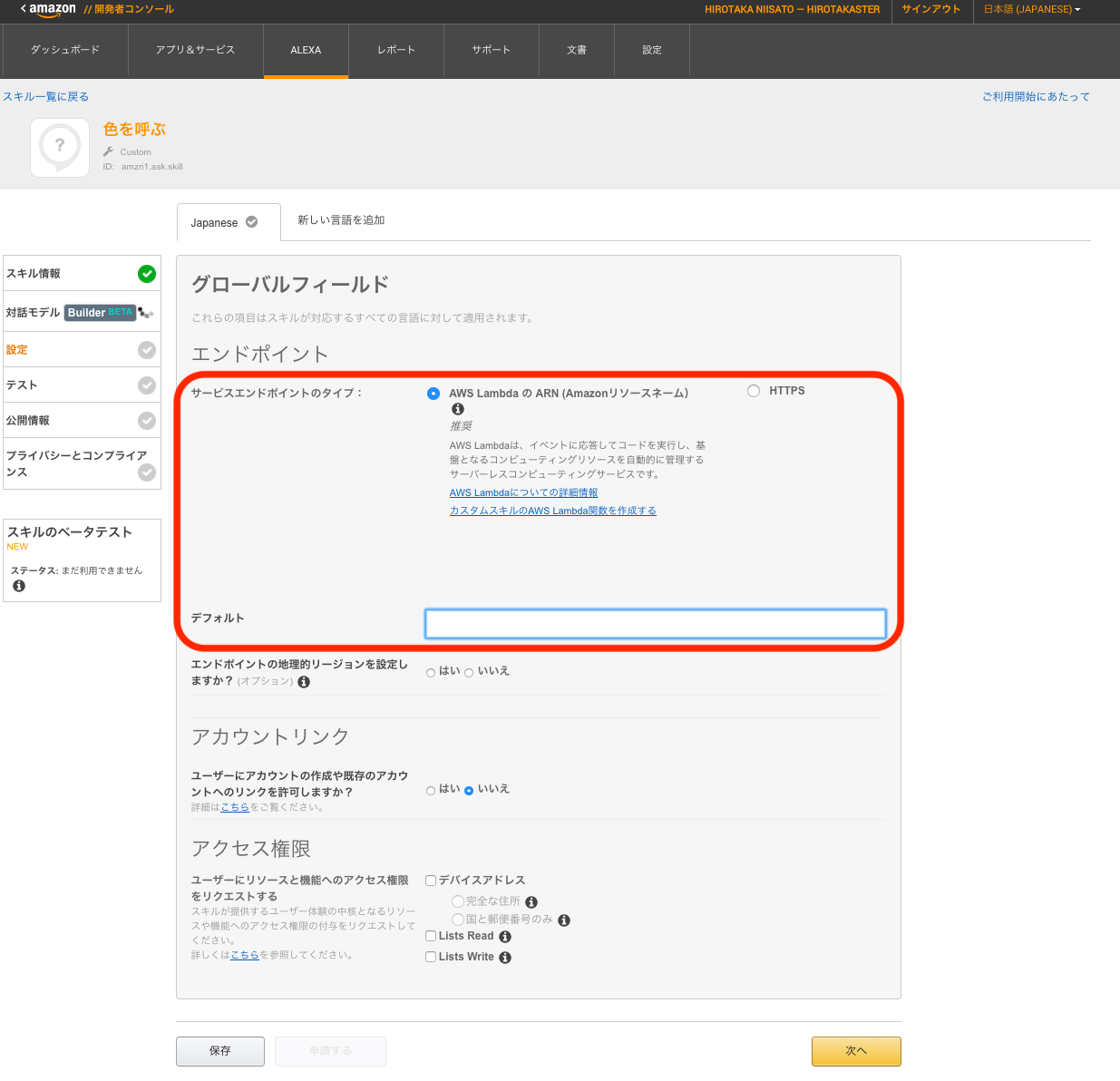
作ったLamdaのARNを”デフォルト”という部分に入れて(arn:lambda:…という文字列)、”次へ”をクリック
2. Alexa上でテスト
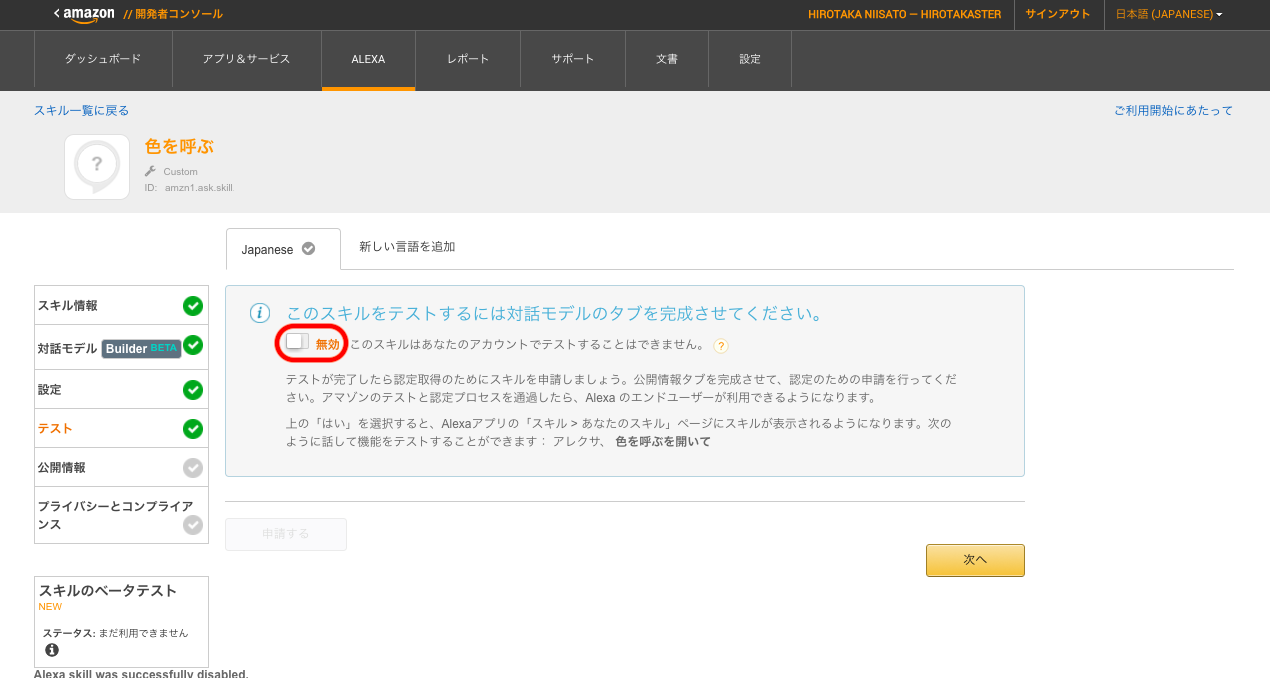
Alexaのテスト画面。”無効”となっているため、クリックして有効にする。
3. サービスシュミレーター
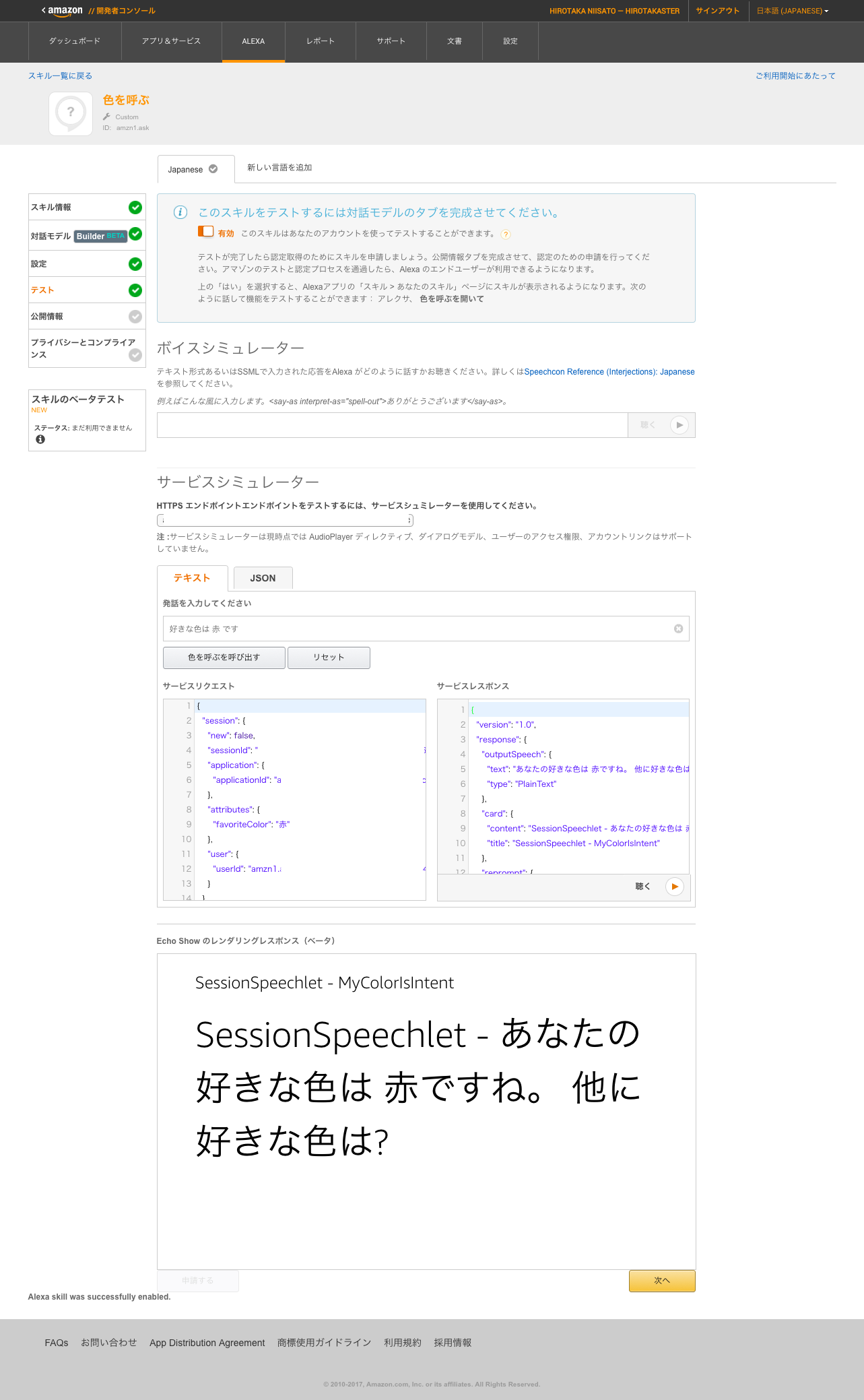
少し画面のしたに行くと”サービスシュミレーター”があるから「好きな色は赤です」と入れて、”色を呼ぶを呼び出す”をクリックすると結果が表示される。
スキルの開発の流れはここまでで終わり。シュミレータでテストを行ったり、いちいちAlexaに話しかけるのが面倒な時はボイスシュミレーターで話させたりも出来る。
あとは自分でアプリを作ったり、音声で遊んだり。外部連携をLambdaでやって、カメラと連動させて「いまのお家の状態を写真を撮ってメールで送って」といったセキュリティデバイス化させたり、LINEと連動させたりするのも面白いと思われ。
スキルタイプで、カスタムは一般的な対話で遊べるけど、スマートホームAPIは使ってみるとかなり面白いと思う。自分はスマートホームAPIでデバイス連携をさせた時、簡単で美しい流れにちょっぴり感動してしまった。
あとプログラムを書くのが苦手で、とりあえずRSSフィードだけ読ませてみたい…という時はフラッシュブリーフィングでサクット作るのもアリだと思われ。”マイチャンネル”みたいな扱いとしても使える。
■ その他
1. Lambdaの応答の日本語化
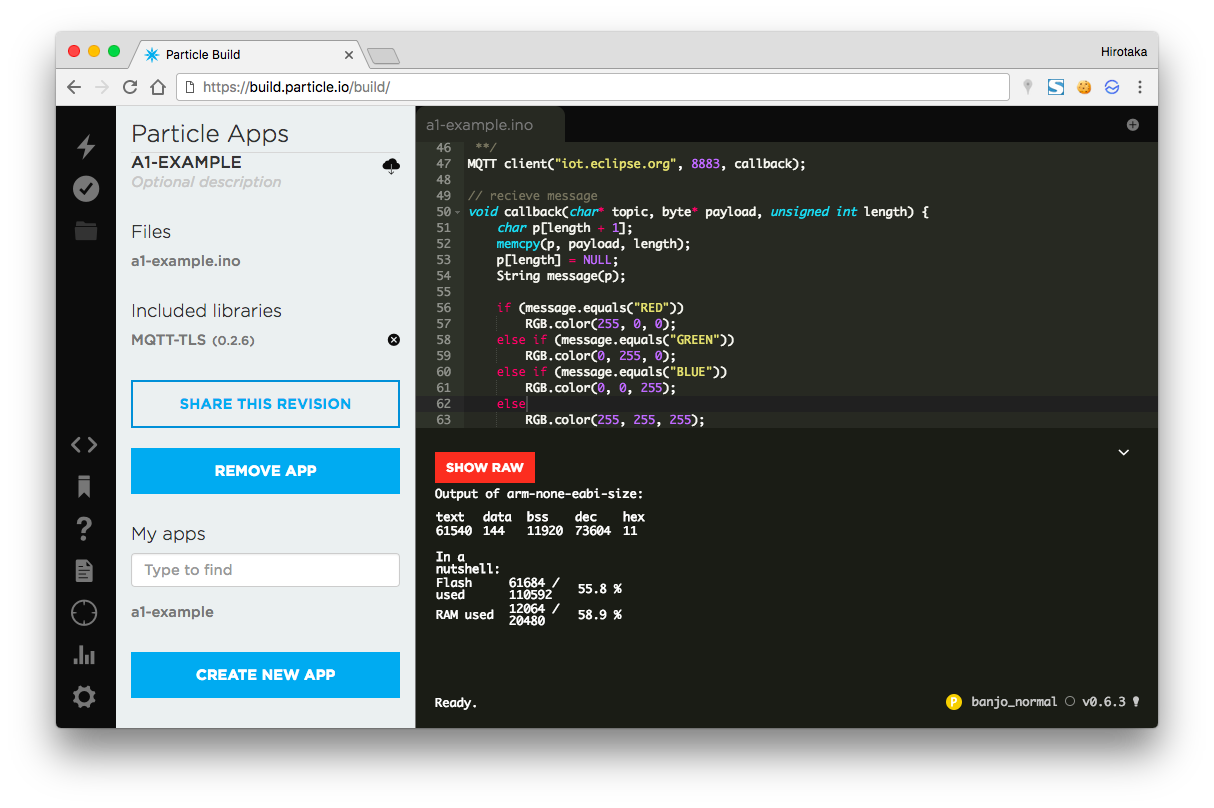
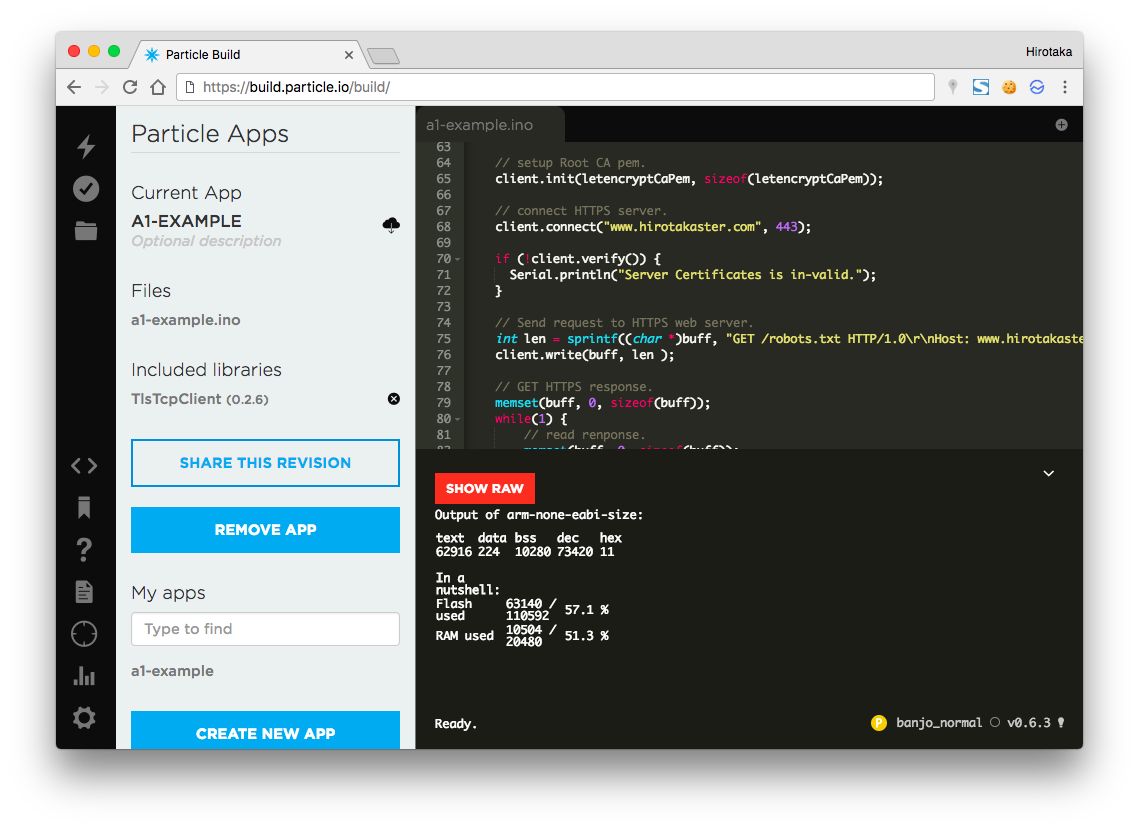
サンプルのColor-me-expertは日本語を戻していない。ただ、普通にPythonのプログラムで応答の文字列の部分を日本語にしてutf-8(# coding:utf-8)をコードの頭に追加すれば、日本語を利用することができる。以下はサンプル中に日本語をいれたもの(超簡単)。
日本語とは関係ないけど、ここでの注意点は”lambda_handler(event, context):”でAlexaアプリのIDを指定して、作ったAlexaスキルからしか実行できないように制限をしている。
# coding:utf-8
from __future__ import print_function
# --------------- Helpers that build all of the responses ----------------------
def build_speechlet_response(title, output, reprompt_text, should_end_session):
return {
'outputSpeech': {
'type': 'PlainText',
'text': output
},
'card': {
'type': 'Simple',
'title': "SessionSpeechlet - " + title,
'content': "SessionSpeechlet - " + output
},
'reprompt': {
'outputSpeech': {
'type': 'PlainText',
'text': reprompt_text
}
},
'shouldEndSession': should_end_session
}
def build_response(session_attributes, speechlet_response):
return {
'version': '1.0',
'sessionAttributes': session_attributes,
'response': speechlet_response
}
# --------------- Functions that control the skill's behavior ------------------
def get_welcome_response():
""" If we wanted to initialize the session to have some attributes we could
add those here
"""
session_attributes = {}
card_title = "ようこそ"
speech_output = "これは好きな色のサンプルアプリでーす "
reprompt_text = "好きな色を言ってね。 "
should_end_session = False
return build_response(session_attributes, build_speechlet_response(
card_title, speech_output, reprompt_text, should_end_session))
def handle_session_end_request():
card_title = "おわりです"
speech_output = "サンプルを使ってもらってありがと"
should_end_session = True
return build_response({}, build_speechlet_response(
card_title, speech_output, None, should_end_session))
def create_favorite_color_attributes(favorite_color):
return {"favoriteColor": favorite_color}
def set_color_in_session(intent, session):
card_title = intent['name']
session_attributes = {}
should_end_session = False
# この Color がSlotで設定した名前
# intent['slots']['Color']['value'] で値を取得できる。
if 'Color' in intent['slots']:
favorite_color = intent['slots']['Color']['value']
session_attributes = create_favorite_color_attributes(favorite_color)
speech_output = "あなたの好きな色は " + \
favorite_color + \
"ですね。 " \
"他に好きな色は?"
reprompt_text = "好きな色を言ってね。 "
else:
speech_output = "色が分からなかったよ。もういちど言って "
reprompt_text = "色が分からなかったよ。 " \
"好きな色は赤ですとかって言って "
return build_response(session_attributes, build_speechlet_response(
card_title, speech_output, reprompt_text, should_end_session))
def get_color_from_session(intent, session):
session_attributes = {}
reprompt_text = None
if session.get('attributes', {}) and "favoriteColor" in session.get('attributes', {}):
favorite_color = session['attributes']['favoriteColor']
speech_output = "あなたの好きな色は " + favorite_color + \
"です。終わります。"
should_end_session = True
else:
speech_output = "私はあなたが好きな色が分からないです。 " \
"好きな色は赤ですとかって言って。"
should_end_session = False
return build_response(session_attributes, build_speechlet_response(
intent['name'], speech_output, reprompt_text, should_end_session))
# --------------- Events ------------------
def on_session_started(session_started_request, session):
""" Called when the session starts """
print("on_session_started requestId=" + session_started_request['requestId']
+ ", sessionId=" + session['sessionId'])
def on_launch(launch_request, session):
""" Called when the user launches the skill without specifying what they
want
"""
print("on_launch requestId=" + launch_request['requestId'] +
", sessionId=" + session['sessionId'])
# Dispatch to your skill's launch
return get_welcome_response()
def on_intent(intent_request, session):
""" Called when the user specifies an intent for this skill """
print("on_intent requestId=" + intent_request['requestId'] +
", sessionId=" + session['sessionId'])
intent = intent_request['intent']
intent_name = intent_request['intent']['name']
# この部分でIntentで設定した名前で処理を分岐することができる
if intent_name == "MyColorIsIntent":
return set_color_in_session(intent, session)
elif intent_name == "WhatsMyColorIntent":
return get_color_from_session(intent, session)
elif intent_name == "AMAZON.HelpIntent":
return get_welcome_response()
elif intent_name == "AMAZON.CancelIntent" or intent_name == "AMAZON.StopIntent":
return handle_session_end_request()
else:
raise ValueError("Invalid intent")
def on_session_ended(session_ended_request, session):
""" Called when the user ends the session.
Is not called when the skill returns should_end_session=true
"""
print("on_session_ended requestId=" + session_ended_request['requestId'] +
", sessionId=" + session['sessionId'])
# add cleanup logic here
# --------------- Main handler ------------------
def lambda_handler(event, context):
print("event.session.application.applicationId=" +
event['session']['application']['applicationId'])
"""
ここの部分でAlexaアプリのID(applicationId)を設定しておく。このlambdaの関数がAlexaの当該アプリからしか実行できないようにしておく必要あり。
"""
if (event['session']['application']['applicationId'] != "amzn1.ask.skill.XXXXXXXXXXXXXXXXXXXXXXXX"):
raise ValueError("Invalid Application ID")
if event['session']['new']:
on_session_started({'requestId': event['request']['requestId']},
event['session'])
if event['request']['type'] == "LaunchRequest":
return on_launch(event['request'], event['session'])
elif event['request']['type'] == "IntentRequest":
return on_intent(event['request'], event['session'])
elif event['request']['type'] == "SessionEndedRequest":
return on_session_ended(event['request'], event['session'])
2. Alexaの管理画面
作ったアプリはAlexaのスキルで確認できる。
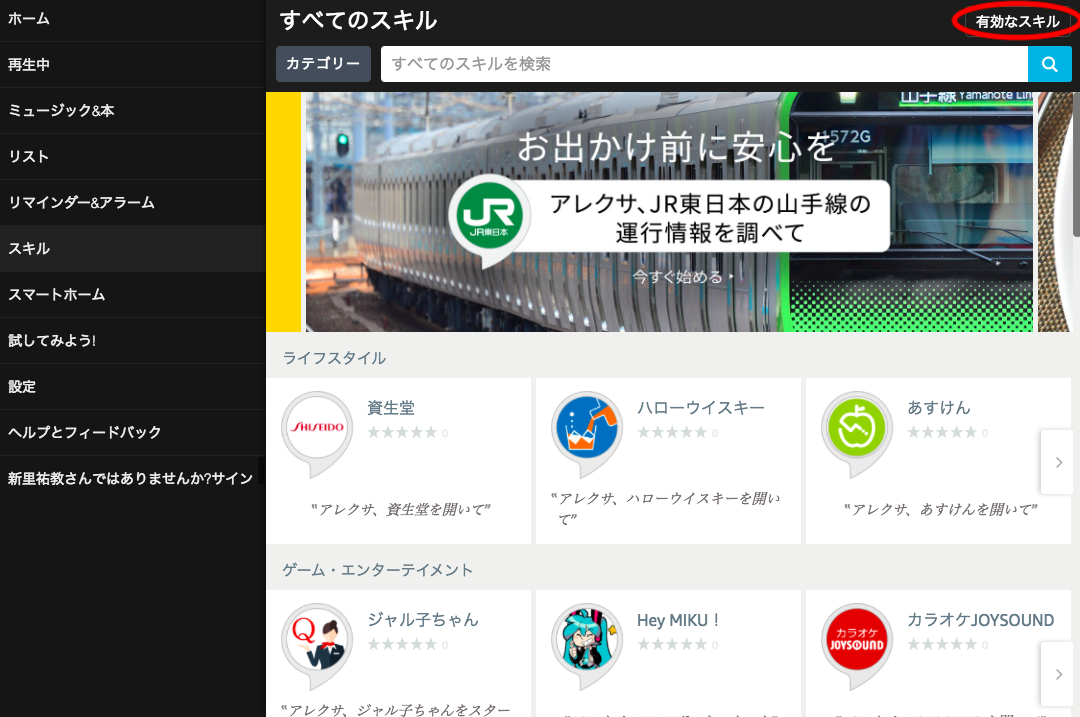
これはAlexa側のスキル管理画面。この右上に、自分がいれたスキル一覧が分かるボタンがあって、見てみると。
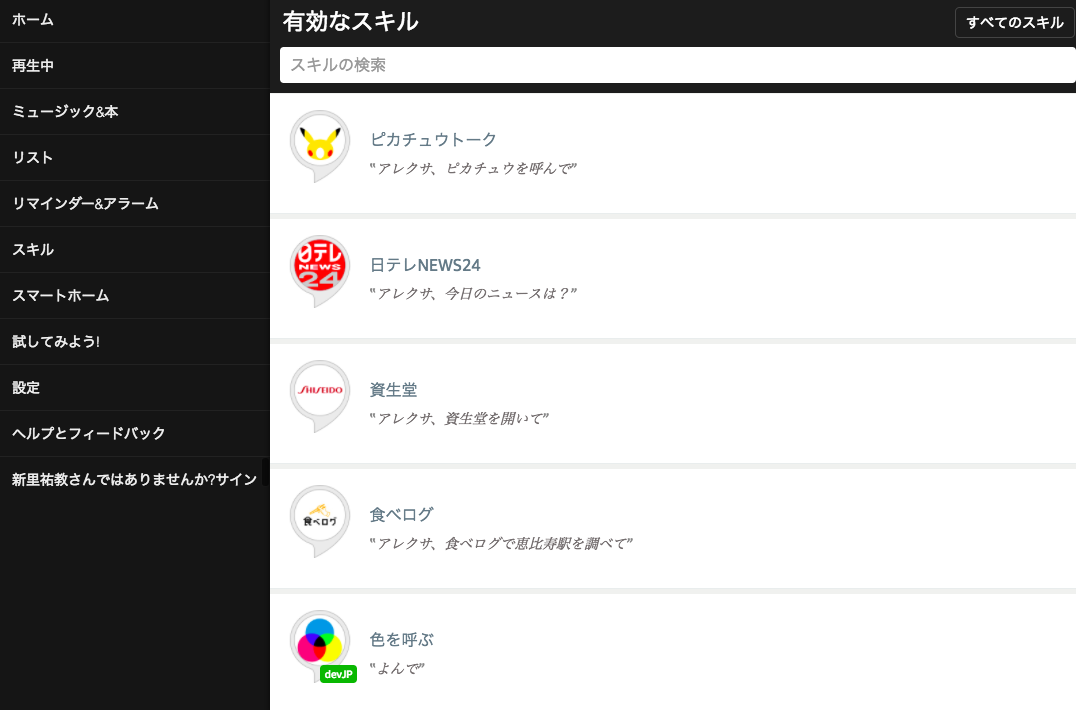
作ったスキル”色を呼ぶ”が入っている。スキルの追加は、スキル一覧から選んで有効にする必要があるが、開発版のタグ(devJP)が付いて、正規のアプリとパット見で区別して分かるのは良い感じ。
2.1. 自作スキルをAlexaに追加するには?
米国版のスキルだと開発するとすぐAlexaのスキル一覧に表示されて分かるのだけど、日本版では「スキルのベータテスト」から追加する流れのようだ(2017/11/15現在)。
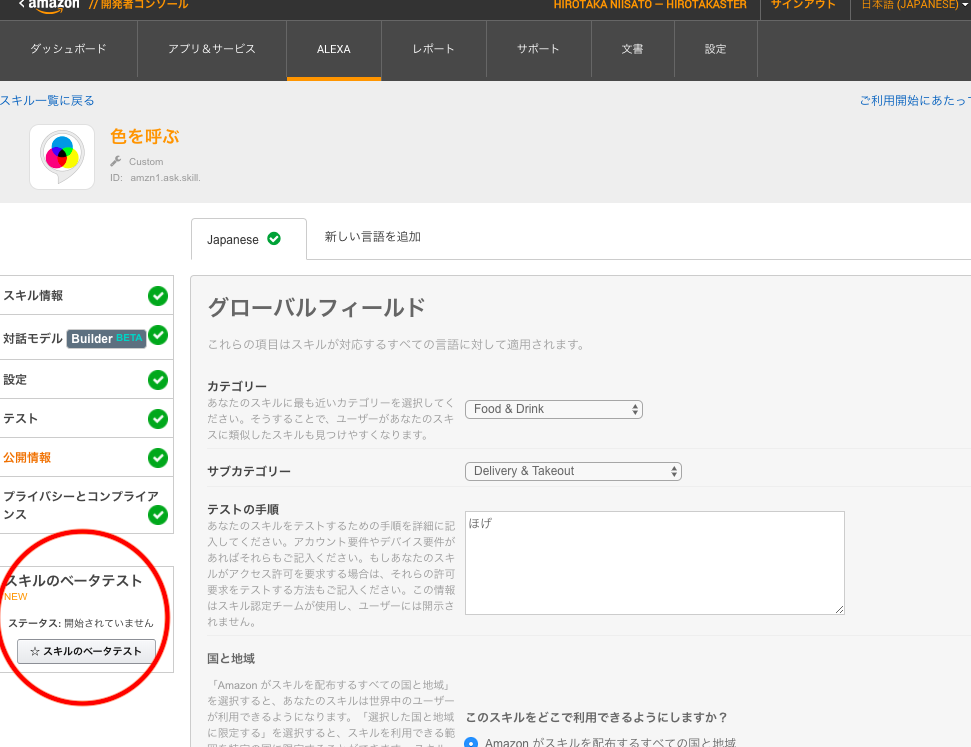
開発者コンソールで、アイコンや色々な情報を入れてリリース申請の直前まで行える状態になると、このボタンが押せるようになる。
すると次のような画面になる。
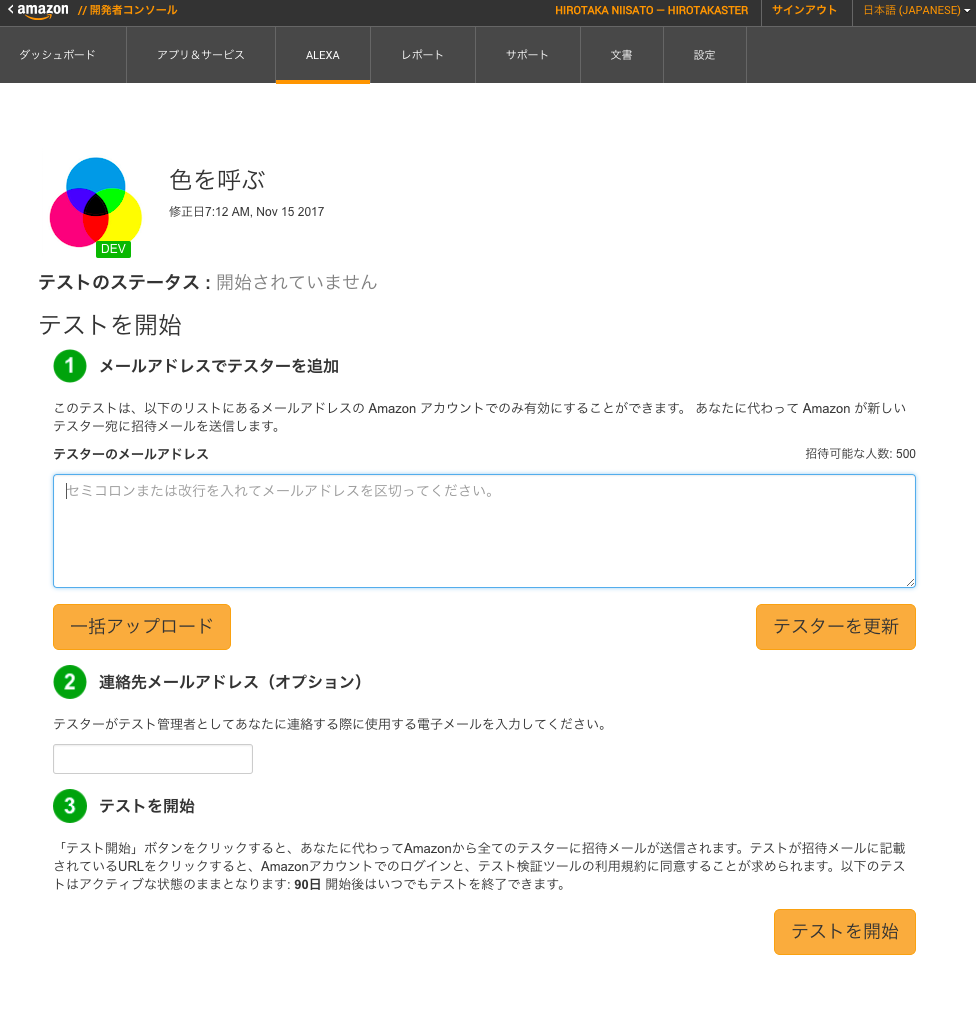
ここでAlexaに登録している人のメアド等を入れて”テストを開始”ボタンを押すと招待URLが送信される。メールの中に”JP customers: To get started, follow this link:”という方のURLリンクがあるから(別の方はUS側のリンク)、そっちをクリックするとスキル一覧に追加されて、実機Echoでテストを進めることが出来る。
3. Lambda利用料金
AWSは従量課金で沢山使うほど課金される。基本的に何かをやろうとすると有料で、Alexaスキルを作ってみたいけど有料なのはなぁ…と思うかもしれない。
自分はAmazonの回し者でも何でもないけど、Lambdaは超安いです。Alexaスキルをさらっと作って動かして開発するくらいなら、課金額は10円もかからないと思われ。サンプルを動かすくらいなら、1円もかからない。気軽に動かしてみよっとー、って感じで全然大丈夫なはず。
4. リリース
実際にスキルを一般にリリースするには、公開情報の設定(スキルのアイコンや説明文)などの設定が必要になる。開発版なら、自分のスキル一覧上で使えるから特に気にする必要はないけど。
設定を適当に入れてリリースすれば一般利用者にすぐ使って貰えるか?と思ったら…Amazonによるリリース判定が待っていた。申請内容はこちら。
スキルの説明文や、Alexaに話しかける内容をちゃんと作らないと、あっさりNGが来る。申請すればすぐ通るんじゃん!!と思ってやってみたら、全くそんな事が無かった(まぁ、ちゃんと作らないとダメというのは当然と言えば、当然だけど)。